Introduction
This article explains how to use Service API to create service-based applications using Golem.
The services API assumes the user would like to treat provider nodes as something like service-hosting platforms, where each activity corresponds to a single instance of some service.
Theoretically, one can try using the task-based model to run services and the services model to run tasks as the models and their usage are not entirely disjoint. The reason why we decided to differentiate them is mostly for convenience and ease of use.
The service model
Golem allows you to launch and control interactive services. A service is, in general Golem terms, a Requestor's process which runs on a node controlled by a Provider and responds to requests (passed i.e. from other nodes of the Golem network) until it is explicitly stopped (usually by a Requestor).
In the Golem service model, the Requestor Agent application specifies the service that is to be instantiated and then controls the service instance throughout its lifecycle in the Golem network.
Service lifecycle
Golem services follows a certain sequence of states:
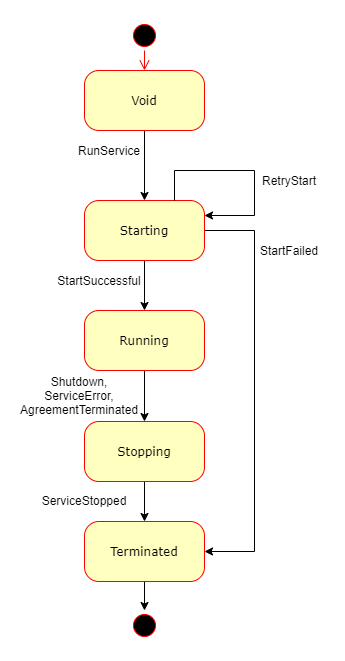
Transitions from one state to another take place as a result of certain events. The events may be triggered by a Requestor (RunService), or Provider (AgreementTerminated), or may be a result of an external phenomenon (like errors of varying nature). Golem SDK's service programming model allows the developer to specify logic that is to be executed in subsequent "active" states of the Service's lifecycle (Starting, Running, Stopping). The HL API controls the transitions between states and hides the "plumbing" of Golem mechanics so that the developer can focus on their service's details.
Requestor Agent service application layout
The developer of a Golem service application needs to follow a certain pattern to implement fundamental aspects of service definition and control. A Service application includes an ExeUnit running on the Provider node, and a Requestor exercising control over that ExeUnit via Golem APIs. The ExeUnit can be e.g. a VM hosting a specific payload application, or a custom ExeUnit controller/wrapper that integrates a third-party service software with the Golem ecosystem. In any case, the Service provisioned on the Golem network will require certain aspects to be specified in the Requestor Agent application.
To define a Golem Service, the developer must create a class/object to indicate the fundamental aspects of the Service to be provisioned. The class must include methods responsible for payload specification (the details of the Demand indicating e.g. the ExeUnit/runtime to be sought on the market), and logic to be executed in "active" states of the service lifecycle.
The code snippets below illustrate a very basic service (a SimpleService), hosted in a standard Golem VM runtime, where service "requests" are the shell commands executed repeatedly on the VM while the service is running.
Specify Demand
The Requestor Agent app must define the "payload" - the detailed specification of the service that is to be provisioned. This specification is then wrapped in a Demand structure and published on the Golem market.
class SimpleService(Service):
@staticmethod
async def get_payload():
return await vm.repo(
image_hash="8b11df59f84358d47fc6776d0bb7290b0054c15ded2d6f54cf634488",
min_mem_gib=0.5,
min_storage_gib=2.0,
)
...A HL API library controls all aspects of the acquisition of suitable Providers, negotiations, and instantiation of Activities. The app needs to indicate the actions to be executed in subsequent "active" states of the Service's lifecycle.
Define Starting logic
Once a Golem activity starts and the Service instance begins its life, the Requestor Agent must indicate all actions to be executed to set up the service.
...
async def start(self):
# perform the initialization of the Service
async for script in super().start():
yield script
script = self._ctx.new_script()
script.run("/golem/run/simulate_observations_ctl.py", "--start")
yield script
...The start() method follows a 'work generator' pattern. It uses a Script instance (acquired via _ctx - the activity's work context) to build a sequence of actions which then gets returned to the service execution engine to be asynchronously relayed to the Provider's runtime. Please take a look at the methods provided by Script objects to get familiar with the possible work steps that can be performed its APIs.
The start() sequence of actions is executed only once in the Service's lifecycle and must result either with success or an indication of failure, in which case, depending on the respawn_unstarted_instances flag of the Golem.run_service() call, the Service's startup is retried on another provider if the flag is True or immediately moves to Terminated state otherwise.
Define Running logic
Once started, the Service transitions to the Running mode - a normal state of operation. In this state, the Requestor Agent may for example; monitor and control the service (either via Golem APIs or contacting the service directly via other means).
...
async def run(self):
while True:
await asyncio.sleep(10)
script = self._ctx.new_script()
stats_result = script.run("/golem/run/simple_service.py", "--stats") # idx 0
yield script
stats = (await stats_result).stdout.strip()
print(stats)
...Note that the Requestor Agent may at some point decide to end the service while it is in the Running state - this ends the actions specified for the Running state and triggers the transition to the Stopping state.
Define Stopping logic
In case the service gets halted, either by Requestor's decision or due to Provider-triggered termination, provided the activity (and thus, the attached WorkContext ) is still available, the Service moves to a Stopping state, in which a Requestor Agent still may have an ability to e.g. recover some artifacts from the service instance, or perform some general clean sweep.
...
async def shutdown(self):
script = self._ctx.new_script()
script.run("/golem/run/simulate_observations_ctl.py", "--stop")
yield script
...Note that the Stopping actions are executed only once in the Service's lifecycle.
In a situation where the termination happens abruptly - e.g. because the provider running the service stops responding or has already terminated the respective activity, Golem won't be able to transition the instance to the stopping state but rather directly to the terminated one. In this case, the shutdown handler won't be executed.
Provisioning the service
Once a service specification class/object is defined, the service can be provisioned on the Golem network. This is done via a Golem execution processor object, which hides all the technical nuances of market interaction, activity tracking, and service state lifecycle:
...
async with Golem(
budget=1.0,
subnet_tag=subnet_tag,
payment_driver=payment_driver,
payment_network=payment_network,
) as golem:
cluster = await golem.run_service(
SimpleService,
num_instances=NUM_INSTANCES,
expiration=datetime.now(timezone.utc) + timedelta(minutes=15))
...The Golem call returns a Cluster of (in this case) SimpleService objects, each representing an instance of the service, as provisioned on the Golem network. The Cluster can be used to control the state of the services (e.g. to stop services when required).
This is all it takes to build a Requestor Agent for a rudimentary VM-based service.
Have a look at a minimal example of a service running on a Golem VM: Hello World tutorial.
Try a more complicated thing with this tutorial. Here we simulate a scenario with a mechanism that periodically polls some external data source and accumulates those observations in a database that can then be queried by the agent that has commissioned it.
- Introduction to Task Model that allows you to execute tasks in a batch-like mode.
You can always reach out to us via our Discord channel